

Highlight
Cheminformatic analysis tools for chemical biologists
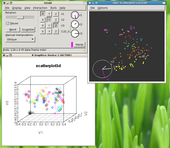
Visualization of Clustering Results in Analysis of Chemical Compounds
Achievement/Results
Cheminformatic, bioinformatic and image database infrastructure development. A fundamental challenge of research today is the effective management and analysis of large sets of data. University of California Riverside’s Center for Plant Cell Biology Chemical Genomics Interdisciplinary Graduate Research and Training program (ChemGen IGERT), funded by the National Science Foundation, fosters the synthesis, discovery and study of bioactive chemicals and disseminates the generated information via the world wide web. Several PhD students in the ChemGen IGERT program are involved in developing free-access platforms for analysis of large and complex datasets. Together, this cyber-infrastructure facilitates the recognition of small drug-like molecules that perturb pathways and processes in an array of biological organisms. This activity directly benefits the students within the program as well as researchers throughout the world.
ChemMine Cheminformatics Infrastructure, Professor Thomas Girke and two ChemGen IGERT associates have developed ChemMine, a free-access database and web toolbox for the mining of chemical compound structures and data from compound screens (http://bioweb.ucr.edu/ChemMineV2; Girke et al. 2005). This chemical genomics Web portal allows users to query compound collections by chemical property, structure, substructure, superstructure, and biological activity. An integrated drug-informatics workbench provides access to a variety of online analysis tools that facilitate study of chemical compounds identified by screening biological organisms for phenotypes or proteins for changes in structure or activity. The analysis of ‘hits’ uses computational approaches such as structure-based clustering (hierarchical, binning) and predictions of chemical properties and drug-likeness. Improvement of ChemMine is an ongoing process.
New components and new algorithms continue to be added by ChemGen IGERT researchers. (1) ChemMineR, a framework for mining of biologically active compounds for specific protein targets developed by Cao and Charisi, Associates in the UC Riverside ChemGen program sponsored by campus matching funds. This software R package allows researchers to mine drug-like compound and screening data sets. ChemmineR contains functions for structural similarity searching, clustering of compound libraries with a wide spectrum of algorithms and utilities for managing complex compound data sets. In addition, it offers visualization functions for compound clusters and chemical structures. The package is well integrated with the ChemMine database and allows bidirectional communications between the two services. The integration of cheminformatic tools with the R programming environment has many advantages, such as easy access to a wide spectrum of statistical methods, machine learning algorithms and graphic utilities. (2) A maximum common substructure-based algorithm for searching and predicting drug-like compounds. ChemGen IGERT associate Cao, under the direction of Thomas Girke, developed an algorithm for applying Maximum Common Substructure method to similarity search of compound databases and prediction of biological activities of chemical compounds with high accuracy. The method utilizes the local similarities between structures of small molecules, and is shown to complement the traditional approaches based on global structural similarities. By combining the new similarity method with traditional ones, the new machine learning method achieves higher accuracy in identifying drug-like and bioactive compounds in large compound databases than traditional methods. Practical application of this algorithm in screening experiments is under investigated by other IGERT fellows.
Address Goals
Example of advanced use of ChemMine. ChemGen IGERT fellow Boyle (bioinformatics/biology) has used the ChemMine tools, under the direction of Thomas Girke, in the design and implementation of a novel chemical-informatics method to identify molecular features that are shared amongst volatile compounds that may participate in binding to specific receptors in plant pests and pollinators. There exist functional assays for identifying ligands of odor receptors, but their labor intensive nature has limited the testing of potential odorants to a few hundred of compounds, which represents an extremely small fraction (<0.1%) of the vast volatile-chemical space. Boyle has performed an in silico screening of potential odorants. First, he performed a quantitative structure-activity relationship (QSAR) analysis of odorant structures for which receptor-activity data is available to select optimal molecular features. Second, he used these features to computationally screen a library of ~240,000 potential odorants, including ones emitted by plants, fruits and humans. Hits were ranked by virtue of their distance in chemical space from known activities. Using this approach Boyle has rapidly and efficiently performed a systematic analysis for the majority of odor receptors present in the insect model, the fruit fly (Drosophila melanogaster). There are two major advantages of performing the initial biological characterization of odorants with Drosophila. First, the responses of most receptors to subsets of odors are available. Second, and importantly, Boyle now collaborates with biologist Anandasankar Ray to validate the accuracy of predictions by directly performing single-sensillum electrophysiology assays with Drosophila using identified compounds. The project provides a student training in bioinformatics with advanced experience in neurophysiology, ultimately of plant pests and pollinators.
(2) ChemGen IGERT fellows Jang Yang (bioinformatics), James Kim (biology), Augusta Jamin (biology), Andrew Defries (biology), Theresa Dinh (biology) and Michelle Brown (biology) have used the ChemMine tools to evaluate structural similarity of compounds identified in screens in studies of plants and fungi. The tool is also routinely used to identify compounds in our libraries or collections that are similar to those with biological activity.
Girke, T, Cheng, L C, Raikhel, N (2005) ChemMine. A compound mining database for chemical genomics. Plant Physiology, 138: 573-577.
Horan, K., Jang C., Bailey-Serres, J., Mittler, R., Shelton, C., Harper, J.F., Zhu, J.-K., Cushman, J.C., Gollery, M. and Girke, T. (2008) Annotating genes of known and unknown function by large-scale co-expression analysis. Plant Physiology. 147 41-57.
Cao Y, Charisi A, Cheng LC, Jiang T, Girke T (2008) ChemmineR: A Compound Mining Framework for R. Bioinformatics: 24, 1733-1734.
