Highlight
A Psychologically Inspired Model for Video-Based Facial Expression Recognition

Fig. 1: Non-verbal communication between a user and an embodied agent.
Achievement/Results
The NSF IGERT on Video-Bioinformatics at the University of California, Riverside has developed bio-inspired computer algorithms to determine the emotional state of people from their apparent facial expressions in continuous video. This has applications in lie detection, video games (Microsoft Xbox Kinect), medicine (treatment of Asperger’s syndrome), human-computer interaction, intelligent tutoring systems and affective computing—where a user talks to a computer and the computer understands the user’s expressions and projects emotion of its own to facilitate non-verbal communication, see Fig. 1.
The two novel contributions to state-of-the-art methods are: (1) A face alignment algorithm that is powerful enough to align faces despite facial dynamics, such as pose, expression and gesture. (2) A method, inspired by the behavior of the human visual system, for selectively processing frames, allowing real-time processing. Current face alignment algorithms fail in extreme pose, or when the face is occluded. We overcome this by warping each face to a target image in an intelligent manner. Facial features are precisely aligned while maintaining the facial expression information within each facial feature. Examples of the algorithm are given in Fig. 2. State-of-the-art systems process every frame of video. They are not fast enough for real-time applications. We selectively process a video in the same way the human visual system (HVS) processes a scene. The HVS follows a saccade-pause-saccade pattern where the duration of the pause is proportional to how much information is changed. The pause between processing a new frame is inversely proportional to the amount of facial motion, e.g., an idle subject needs a single frame to describe the expression (Fig. 3, top), whereas an actively expressing subject needs many frames (Fig. 3, bottom). We sample video frames (in slices) at a rate that is inversely proportional to the dominant frequency; this captures how frequently the information is changing in a video.
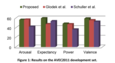
The developed approach was submitted to the Audio/Visual Emotion Challenge 2011, held in the summer, 2011. In the challenge, a user interacted with the Sensitive Artificial Listener, in Fig. 1. The non-verbal feedback was recorded. The objective of the challenge was to detect the emotion expressed by the user. Typically emotion is described in terms of Ekman’s big six: happiness, sadness, fear, surprise, anger and disgust. However, these categories are not exhaustive. A novel representation of emotion is used, proposed by Fontaine et al, where emotion exists along one of the four dimensions: arousal, expectancy, power and valence. The developed approach improved state of the art approach by 10%, see Fig 4. It is our hope that one day computers will be empathetic toward a user’s emotion by understanding expressions, pose and gesture.
References:
A. Cruz, B. Bhanu and S. Yang, “A Psychologically Inspired Match-Score Fusion Model for Video-Based Facial Expression Recognition,” First International Audio/Visual Emotion Challenge and Workshop (AVEC 2011) held in conjunction with 4th Affective Computing and Intelligent Interaction (ACII 2011), Memphis, Tennessee, October 9-12, 2011.
S. Yang and B. Bhanu,” Facial expression recognition using emotion avatar image,” Workshop on Facial Expression Recognition and Analysis Challenge, in conjunction with 9th IEEE Int. Conference Automatic Face and Gesture Recognition, Santa Barbara, March 21-25, 2011. Winner of the International Competition on Facial Expression Recognition.
S. Yang and B. Bhanu, “Understanding discrete facial expressions using emotion avatar image,” IEEE Trans. on Systems, Man and Cybernetics, Part B, Special Issue, Accepted March 16, 2012. In Press.
Address Goals
The activity advances the state-of-the-art in substantial ways. It is an interdisciplinary project at the intersection of cognitive science/psychology and computer science/engineering.
Albert Cruz is an IGERT fellow.